

Descifrando la información genética
Maricela Carrera Reyna, Verónica Jiménez Jacinto y Rosa María Gutiérrez Ríos
Nuestra historia comienza en la década de 1930, en una época en la que la comunidad científica apenas comenzaba a vislumbrar el papel fundamental de los ácidos nucleicos en la transmisión de la información genética. En aquel entonces, no se sabía que el ácido desoxirribonucleico (ADN) y el ácido ribonucleico (ARN) portan las “instrucciones” que gobiernan el funcionamiento y desarrollo de todos los seres vivos. Estos ácidos nucleicos están formados por largas cadenas de pequeñas unidades llamadas nucleótidos, que podemos imaginar como las letras de un alfabeto biológico.
En ese contexto, se sentaron las bases de un conocimiento que se edificó paso a paso gracias al esfuerzo colectivo de científicos y científicas. En los artículos incluidos en este número especial de “Biotecnología en Movimiento” resaltaremos el aporte de mujeres que han sido protagonistas en descifrar el lenguaje genético y en impulsar la bioinformática. Su legado, junto con el de sus colegas, ha permitido que hoy comprendamos en profundidad los mecanismos que rigen la vida.
Del ADN a las proteínas: descifrando el lenguaje de la vida.
Imagina que cada ser vivo es como un enorme libro de instrucciones, escrito únicamente con cuatro letras: A, T, C y G. Para la célula, estás letras son un código que representa a moléculas llamadas nucleótidos, en donde A representa a la molécula adenina, T a la timina, C a la citosina y G a la guanina. Este código, está alojado en una estructura de doble hélice del ADN, que contiene la información esencial para construir y mantener un organismo (Figura 1a). Pero te preguntarás, ¿cómo se convierte este código en las estructuras y funciones esenciales para la vida?
El proceso inicia con la transcripción (Figura 1a). Siendo este proceso similar a que la célula transcribiera un párrafo de un libro (una sección específica del ADN) a un formato entendible para lectores que comprenden un idioma semejante pero no idéntico: el ARN mensajero (ARNm). A diferencia del ADN, el ARNm utiliza uracilo (U) en lugar de timina (T), el cual es tomado por los ribosomas, las “fábricas” celulares encargadas de interpretar o más bien traducir ese mensaje.
En la traducción, el ribosoma “lee y traduce” el mensaje del ARNm en grupos de tres letras, denominados codones, que indican el orden preciso de los aminoácidos (Figura 1b). Los codones forman un nuevo alfabeto de 20 moléculas llamadas aminoácidos (Figura 1c).
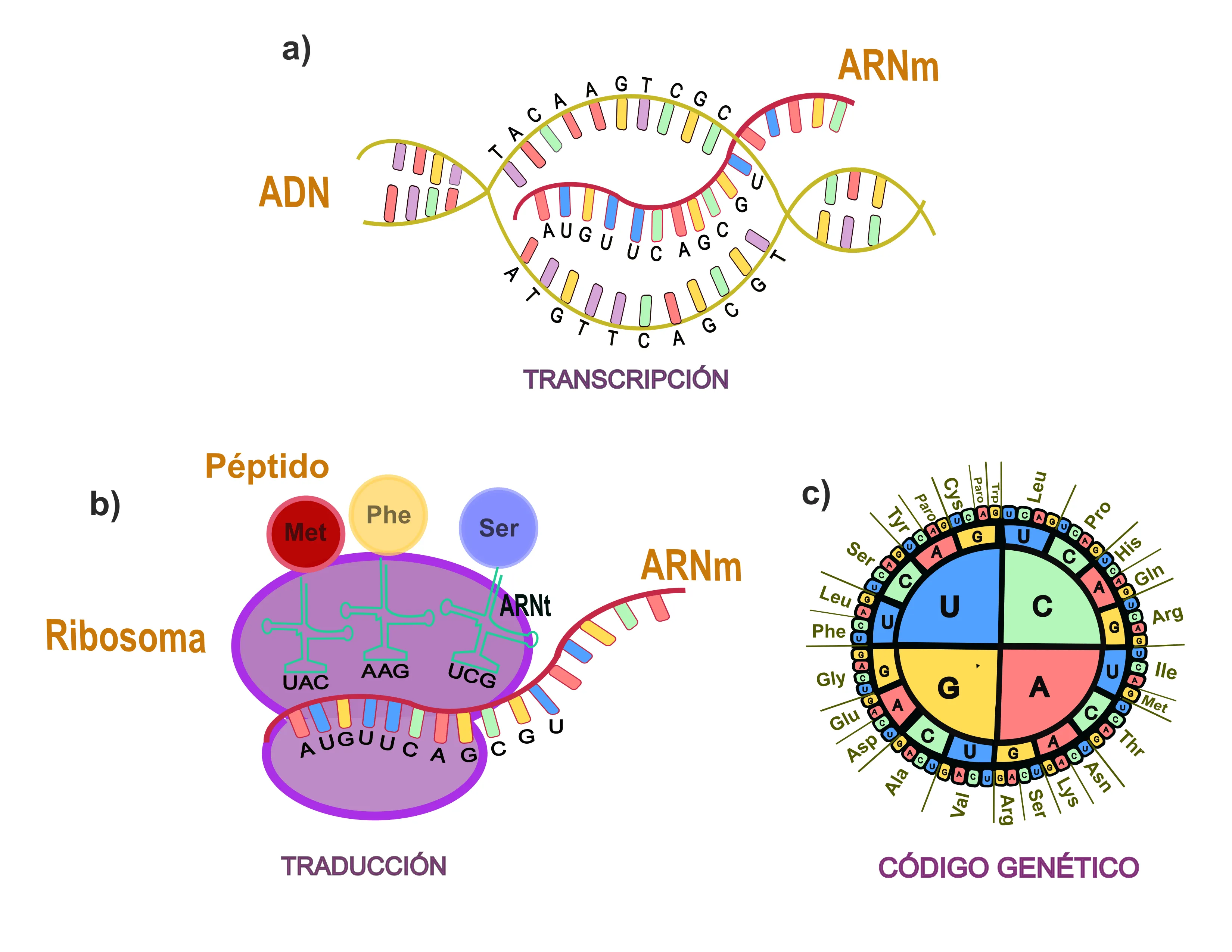
Figura 1. a) Esquema del proceso de transcripción en donde una copia de ARNm, se sintetiza a partir de una secuencia de ADN de un gen. b) Esquema del proceso de traducción, que muestra la síntesis de un péptido usando la información genética que lleva el ARNm. c) El código genético define cada aminoácido de una proteína o polipéptido en términos de una secuencia específica de tres nucleótidos llamados codones.
Los aminoácidos, podríamos compararlos con cuentas únicas de un collar, que se unen mediante enlaces llamados peptídicos para formar largas cadenas (Figura 2). Estas cadenas se pliegan en estructuras tridimensionales complejas, dando lugar a las proteínas, verdaderas arquitectas y obreras de la vida. Desde las enzimas que convierten a los alimentos en energía y nuevas moléculas constructoras, hasta los anticuerpos que nos protegen de enfermedades, las proteínas son esenciales en todos los procesos vitales.
No obstante, conocer la función de una proteína en un organismo no es trivial, por lo que es necesario realizar experimentos en el laboratorio, que revelen cómo estas moléculas especializadas operan en las células.
Ahora que sabes qué moléculas almacenan la información genética y cómo se convierte el mensaje del ADN en proteínas, repasemos los hechos clave que condujeron a este conocimiento.
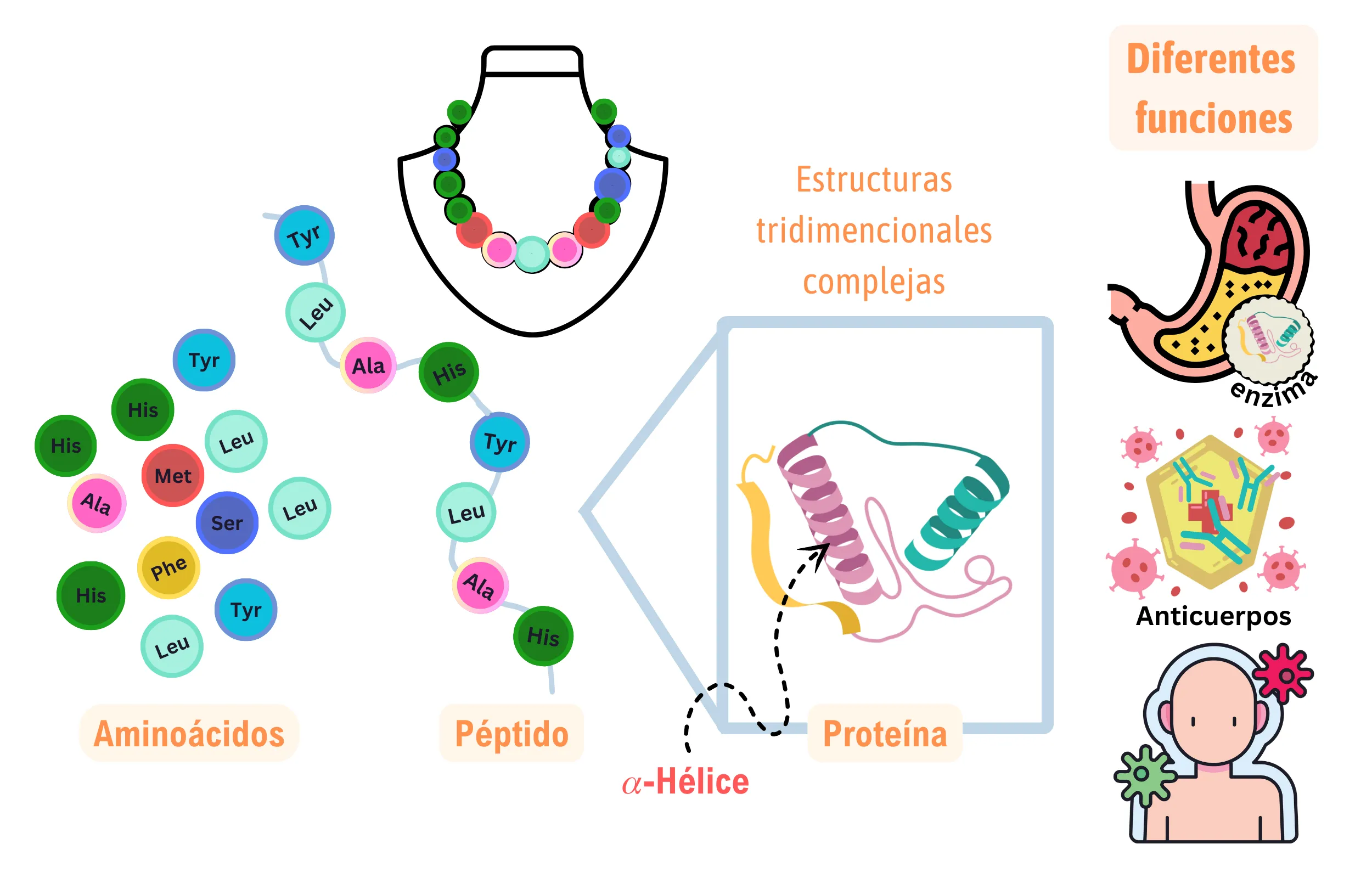
Figura 2. Se muestra cómo los aminoácidos, que son las unidades básicas, se ensamblan en cadenas llamadas péptidos, comparándolo con un collar de cuentas. Luego, estas cadenas adquieren estructuras tridimensionales complejas para formar proteínas funcionales. También se ilustran diferentes funciones de las proteínas, como las enzimas (que facilitan reacciones químicas en el tracto digestivo), o de los anticuerpos (actores del sistema inmunológico, esenciales en la defensa del cuerpo ante los diferentes patógenos).
Los rayos X como promotores del conocimiento
El avance en la comprensión de estructuras como el ADN y las proteínas se vio impulsado por técnicas innovadoras como la difracción de rayos X. El químico Linus Pauling, uno de los científicos más influyentes del siglo XX, publicó en 1939, “La naturaleza del enlace químico”, en el que explicó cómo los átomos se unen para formar moléculas. Gracias a esta técnica, se pudo analizar la estructura tridimensional de las moléculas, revelando detalles fundamentales sobre la organización y estructura de los aminoácidos, esas pequeñas “cuentas” formando los péptidos, con tres componentes esenciales: un grupo amino, un grupo carboxilo y una cadena lateral única.
Uno de los descubrimientos más impactantes fue la identificación de la hélice α. En esta estructura, la cadena de aminoácidos se enrolla en una espiral compacta y elegante, estabilizada por enlaces de hidrógeno.
Pauling demostró que esta estructura es clave para la estabilidad y función de muchas proteínas, lo que ayudó a comprender cómo estas moléculas adoptan su forma tridimensional para desempeñar su papel en los seres vivos. Su trabajo no solo transformó el estudio de las proteínas, sino que también sentó las bases para descifrar la estructura de otra molécula fundamental para la vida: el ADN.
Rosalind Franklin y la estructura del ADN
El uso de la cristalografía de rayos X (Figura 3 A), y los conocimientos desarrollados a partir de ella fueron fundamentales para que, en la década de 1950, James Watson y Francis Crick propusieran el modelo de la doble hélice del ADN, la molécula que almacena la información genética de todos los seres vivos. Sin embargo, este descubrimiento no habría sido posible sin el trabajo de la química Rosalind Franklin, experta en cristalografía de rayos X.
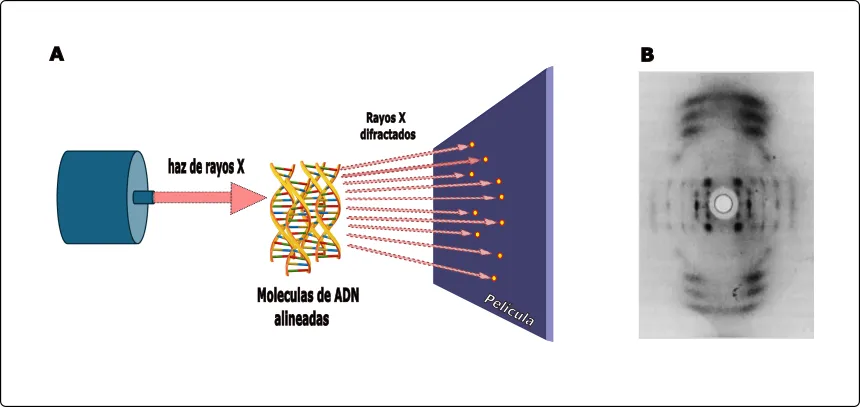
Figura 3. Estructura cristalográfica del ADN. A) Proceso simplificado de la obtención de una imagen de rayos X a partir de moléculas de ADN alineadas. B) La famosa foto 51 mostrando una imagen cristalográfica de la molécula de ADN. Idea tomada y modificada de Biophysics 2S03 Lab Manual Copyright ©.
Franklin logró capturar la famosa “Fotografía 51”, una imagen que reveló la estructura del ADN, Figura 3B). Su patrón de difracción mostró que la molécula tenía una forma helicoidal, es decir, una estructura en espiral similar a un resorte o una escalera de caracol. Para entender mejor esta estructura, es importante saber que el ADN está compuesto por unidades más pequeñas llamadas nucleótidos. Cada nucleótido está formado por tres componentes: un azúcar llamada desoxirribosa, una base nitrogenada (A, T, C y G) y un grupo fosfato, que permite que los nucleótidos se conecten entre sí, formando la columna vertebral de la molécula (Figura 4).
Uno de los aportes más importantes de Franklin fue demostrar que los grupos fosfato se encuentran en la parte externa de la molécula, mientras que las bases nitrogenadas están en el interior, formando los "peldaños" de la doble hélice (Figura 4). Esta disposición es crucial, ya que permite que el ADN sea químicamente estable y pueda replicarse con precisión. A pesar de la relevancia de su trabajo, Franklin no recibió el reconocimiento que merecía. En 1962, el Premio Nobel fue otorgado a Watson, Crick y Maurice Wilkins (jefe de Franklin), mientras que su contribución fue minimizada y solo Wilkins la mencionó brevemente en su discurso de aceptación del premio. A esto debemos agregar que Franklin murió a los 37 años, en 1958 antes de que se otorgara el Premio Nobel a sus colegas [1]. Las reglas del Premio Nobel impiden hacer reconocimientos póstumos por lo que, a pesar de su importante contribución, no hubiera recibido este reconocimiento. Sin embargo, con el tiempo, la comunidad científica ha reconocido su papel fundamental en el descubrimiento de la estructura del ADN. Hoy en día, Rosalind Franklin es celebrada como una pionera en la biología estructural, y su legado ha inspirado a generaciones de científicas y científicos en todo el mundo.
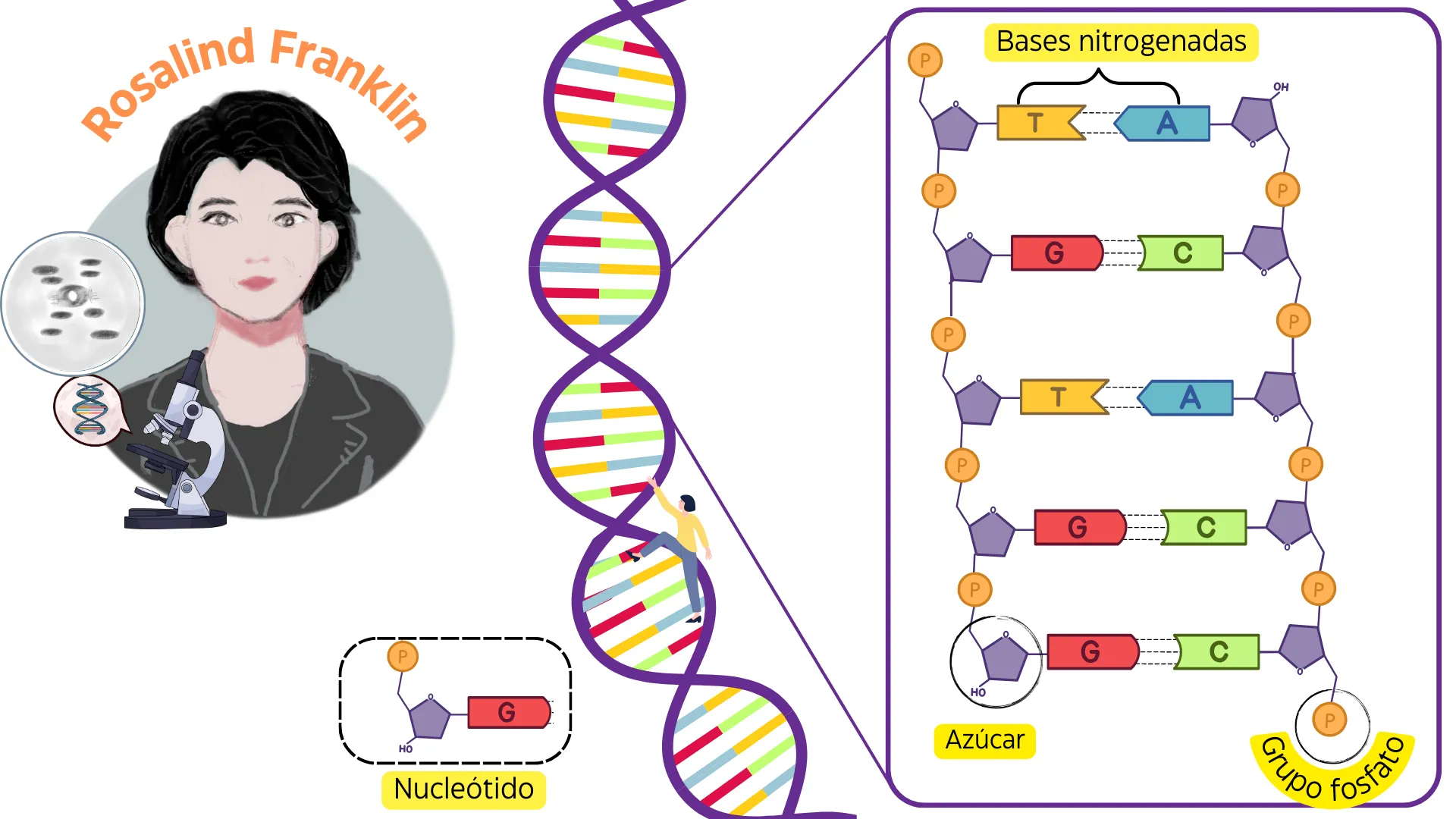
Figura 4. Esta ilustración resalta la contribución de Rosalind Franklin al descubrimiento de la estructura del ADN. A la izquierda, una representación caricaturizada de Franklin aparece junto a una imagen de difracción de rayos X, similar a la icónica "Fotografía 51", clave para identificar la doble hélice. A la derecha, un esquema detallado muestra la composición del ADN: bases nitrogenadas (adenina (A), timina (T), citosina (C) y guanina (G)), azúcares y grupos fosfato, componentes esenciales de los nucleótidos.
Accediendo a las secuencias de la vida
A finales de 1950, usando la ya mencionada técnica de cristalografía de rayos X, fue posible establecer la secuencia de aminoácidos y la estructura tridimensional que describe a la insulina, lo que impulsó el desarrollo de nuevas técnicas para obtener las secuencias de aminoácidos que forman las proteínas. En este trabajo fue pionero el científico suizo Pehr Edman, quien desarrolló el método conocido de degradación de Edman [2] (Figura 5). Este método permite degradar aminoácido por aminoácido a un polipéptido (polímero pequeño de aminoácidos) con una longitud teórica de hasta 50-60 aminoácidos, aunque en la práctica su longitud no superaba los 30 aminoácidos. Entonces, para secuenciar completamente una proteína, se debía romper en fragmentos de aproximadamente 30 aminoácidos (esto se lograba exponiendo a las proteínas que se querían secuenciar a otras proteínas digestivas llamadas proteasas y cuya función es precisamente romper proteínas para que las podamos digerir y absorber) que una vez secuenciados se ensamblaban entre sí y se deducía la secuencia de la proteína completa.
En 1967, Edman automatizó el proceso, lo que permitió secuenciar 15 familias de proteínas en los siguientes 10 años y distribuir al menos 100 equipos de secuenciación para 1973 [3]. Estos avances fueron fundamentales para ampliar nuestro conocimiento sobre las biomoléculas y sentaron las bases para el desarrollo de disciplinas que, décadas más tarde, permitirían estudiar los sistemas biológicos a gran escala.
A medida que las tecnologías de secuenciación mejoraban y los volúmenes de datos biológicos crecían exponencialmente, se hizo evidente la necesidad de herramientas computacionales para analizarlos e interpretarlos. Ahora los científicos tenían en sus manos un rompecabezas gigantesco, con miles de piezas dispersas: genes, proteínas, metabolitos, entre otros, pero para comprender a la biología de los organismos requerían ensamblar esas piezas. No obstante, hacerlo manualmente era imposible.
Fue entonces cuando emergieron nuevas disciplinas que buscaban entender la biología desde una perspectiva integral, analizando no solo elementos aislados, sino sus interacciones dentro de sistemas completos. Así nacieron las ciencias ómicas, un conjunto de campos de estudio que exploran los diferentes niveles de organización molecular en los organismos, desde los genes hasta las proteínas y más allá…
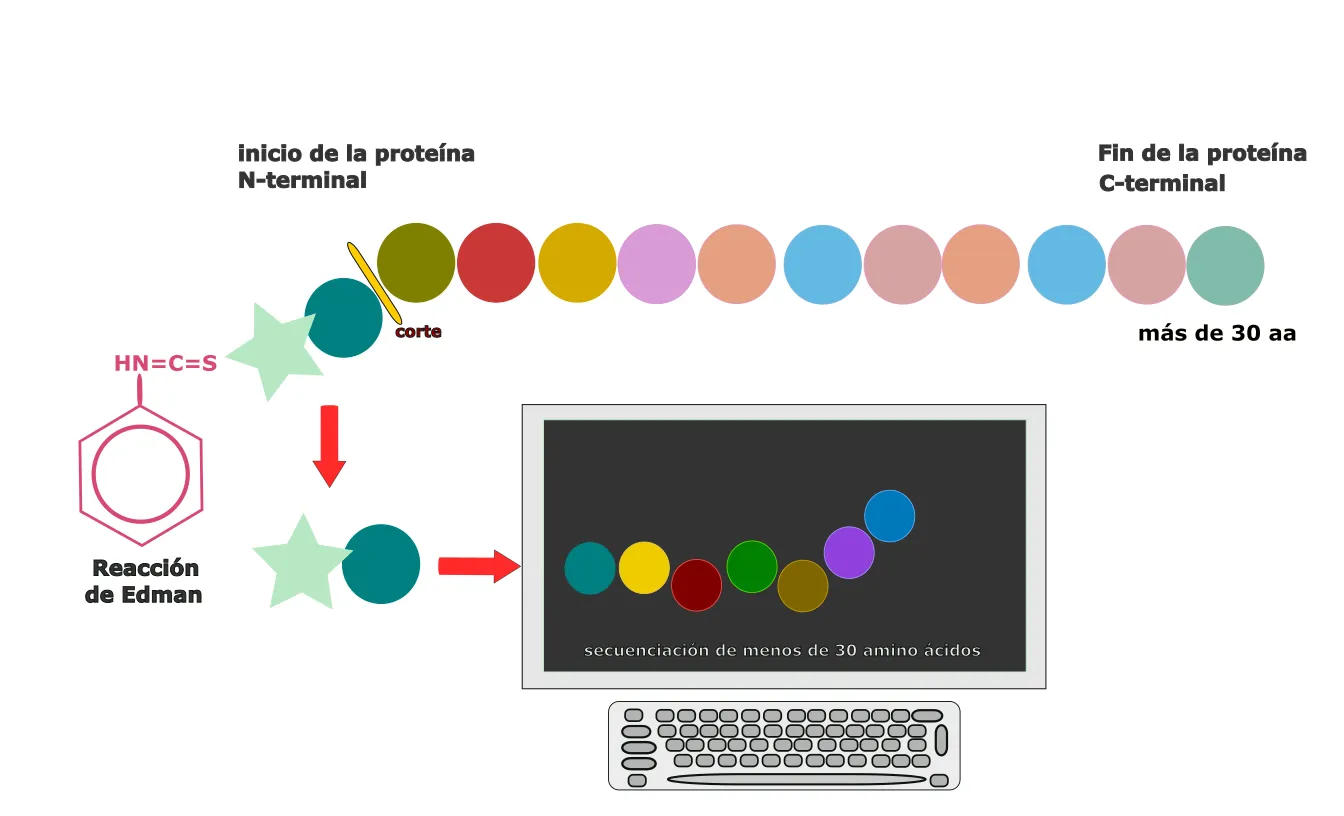
Figura 5. Secuenciación de Edman. Primera tecnología que permitió secuenciar una fracción de proteína (péptido menor a 30 aminoácidos).
Además de los avances en ciencias como bioquímica y biología molecular, para que las ciencias-ómicas se pudieran desarrollar tuvo que desarrollarse la bioinformática. Pero te preguntarás ¿qué es la bioinformática?
Bioinformática: eje rector de las ciencias ómicas
Las ciencias ómicas dependen de la bioinformática, una disciplina que combina otras disciplinas como biología, computación y estadística (entre otras) para analizar grandes volúmenes de datos biológicos (Figura 6). Gracias a la bioinformática, hemos logrado entender cómo se organiza, transmite y regula la información genética en millones de organismos, tanto macro como microscópicos.
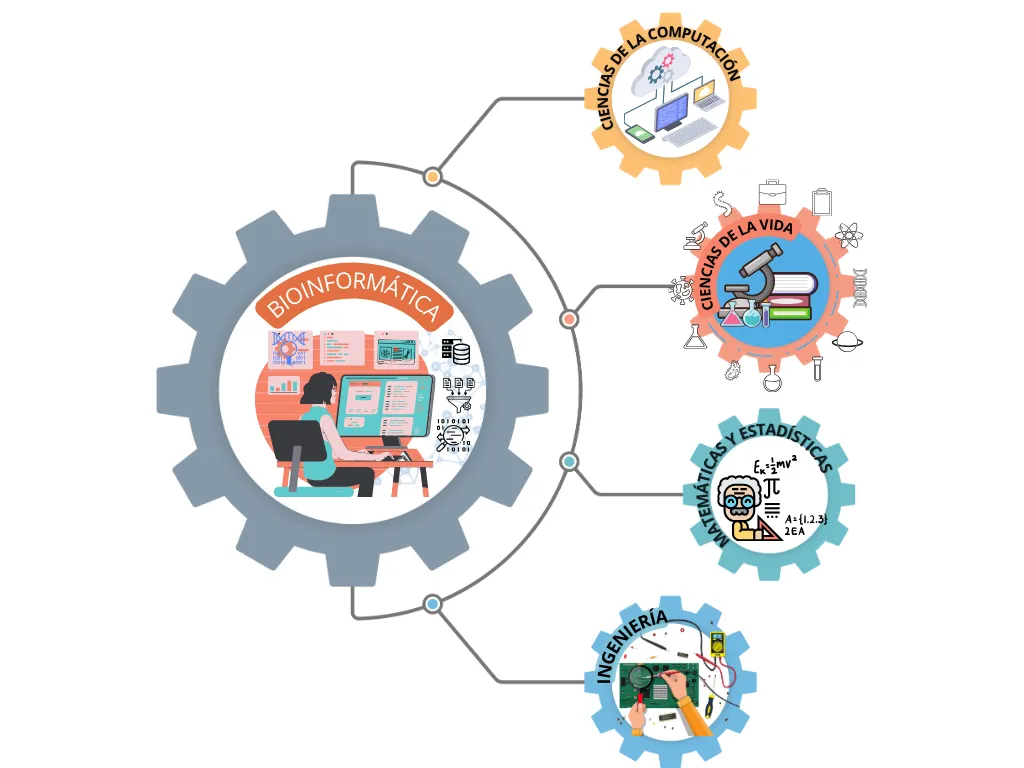
Figura 6. Bioinformática. La bioinformática una ciencia integradora que conecta muchas disciplinas y tecnologías para descifrar los secretos de la vida. Combina conocimientos de las ciencias de la vida, como la biología, la medicina y la evolución; herramientas de las ciencias de la computación, como inteligencia artificial y ciencia de datos; y fundamentos de la ingeniería, las matemáticas y la estadística. Este enfoque interdisciplinario permite comprender cómo funcionan los seres vivos, desde el nivel molecular hasta el impacto en ecosistemas completos, abriendo puertas a avances en salud, medio ambiente y biotecnología.
En las últimas dos décadas, los avances en las tecnologías de secuenciación de ADN y computadoras con procesadores de alto rendimiento nos han permitido identificar y explorar los genomas (conjunto de genes que conforman a un organismo), transcriptomas (conjunto de genes que se expresan dentro de la célula) y proteomas (el conjunto de proteínas codificadas en los genomas), tanto de microorganismos cultivables como de los microorganismos que no podemos cultivar y crecer en el laboratorio, debido a que habitan ambientes que no podemos replicar artificialmente.
Como ejemplos de los ambientes donde viven los microorganismos no cultivables, tenemos el intestino de muchos organismos, el agua y el sedimento marino en distintas profundidades, suelos y ríos, donde las condiciones de nutrientes, temperatura, presión, y los mensajes químicos que estos microorganismos necesitan para vivir, son imposibles de reproducir (ver Biotecnología en Movimiento, Año 10 Número 37, https://biotecmov.ibt.unam.mx/numeros/37/4.html). La ciencia ómica que estudia los conjuntos de genomas de los microorganismos que habitan en estos ambientes se conoce como metagenómica (que significa: más allá de un solo genoma, ya que se secuencian al mismo tiempo todos los genomas de todos los organismos que se encuentran en la muestra), y la información genética codificada se conoce como metagenoma (Figura 7).
A lo largo de la historia, las mujeres han desempeñado un papel clave en el descubrimiento de la estructura del ADN y en el desarrollo de herramientas bioinformáticas. Tal es el caso de Margaret Oakley Dayhoff y Grace Murray Hopper, centrales en el desarrollo de la bioinformática. Su legado ha pavimentado el camino para las futuras generaciones de científicas, quienes continúan revolucionando la genética y la bioinformática y otras áreas, con sus descubrimientos.
Pero ¿cómo funciona la bioinformática en el análisis de genomas y metagenomas?, ¿quiénes son las mujeres que han contribuido al avance de este conocimiento? Esto te lo contaremos en el artículo “Ecos del algoritmo: la evolución de la bioinformática en México” que se incluye en este número.
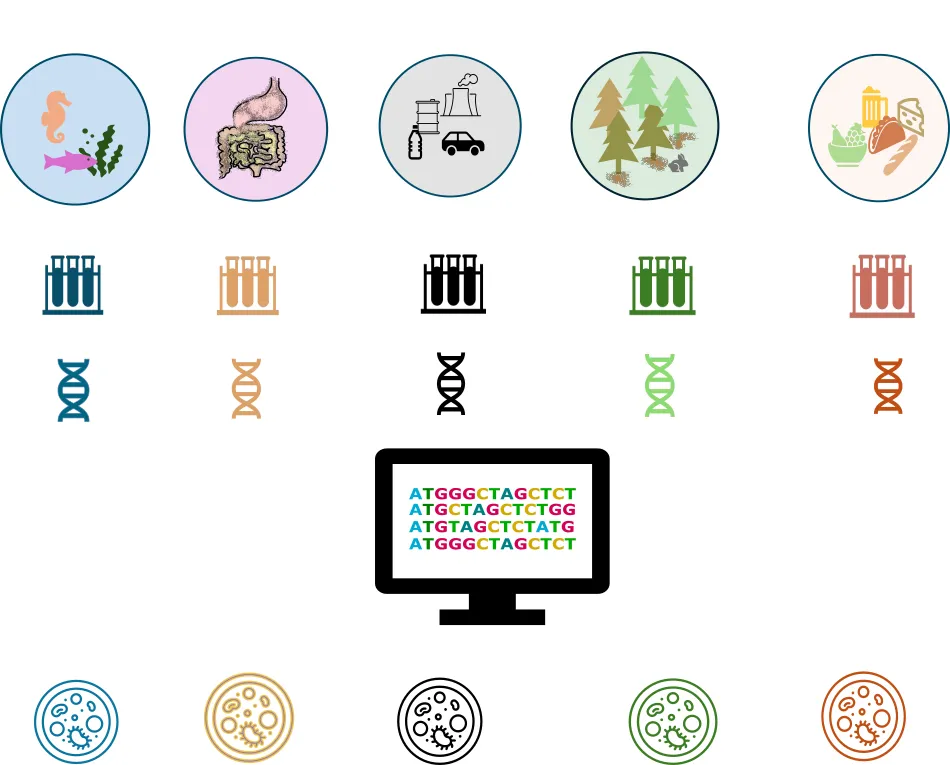
Figura 7. Metagenómica. A través de la bioinformática podemos explorar los distintos ecosistemas del planeta. Extrayendo el ADN de muestras de distintos ambientes que son secuenciadas y analizadas con métodos computacionales.
Referencias
- Rosalind Franklin, la olvidada científica detrás del descubrimiento de la estructura del ADN, uno de los más importantes para la medicina moderna. https://www.bbc.com/mundo/noticias-44225714.
- Edman, P. Method for Determination of the Amino Acid Sequence in Peptides. Acta Chemica Scandinavica. 1950, 4, 283.
- Niall HD. Automated Edman degradation: the protein sequenator. Methods Enzymology. 1973; 27:942-1010. DOI: 10.1016/s0076-6879(73)27039-8.
Lecturas recomendadas
- Martínez-Barreneche J. La bioinformática como herramienta para la investigación en salud humana. Salud Publica Mex. 2007; 49: 64-6. https://saludpublica.mx/index.php/spm/article/view/7444/9794
- Portillo-Bobadilla T., Pérez-Hernández B., Pérez-Hernández V., y Hernández-Guzmán M. Una introducción a la bioinformática: avances en la biología y ciencias de la salud. Memoria del XLIX Taller de Actualización Bioquímica, Facultad de Medicina; UNAM. 2022, 1-12. http://biosensor.facmed.unam.mx/tab/wp-content/uploads/2022/06/1-Portillo.pdf
Comparte este artículo en redes sociales

Acerca de las autoras
Verónica Jiménez. Estudió la licenciatura en Matemáticas aplicadas y computación. Ha trabajado en proyectos bioinformáticos durante los últimos 23 años. Participó en la secuenciación de uno de los primeros organismos secuenciados en Latinoamérica: Rhizobium etli, en 2006. Es co-fundadora de RLadies Cuernavaca y tiene la certificación de Software Carpentries para la formación de instructores de ese software. También es la responsable del sistema de Gestión de Calidad de ISO 9001 del Laboratorio Nacional de Apoyo Tecnológico a las Ciencias Genómicas. Maricela Carrera Reyna. Estudiante de doctorado con interés en la aplicación de métodos computacionales para la exploración de genomas microbianos. Es especialista en lenguajes de programación y socia fundadora de PyLadies Cuernavaca. Rosa María Gutiérrez Ríos es investigadora del Instituto de Biotecnología en el área de genómica y biología computacional. Sus investigaciones están enfocadas en entender a nivel de sistema, las interacciones genético-metabólicas que modulan la expresión de los genes en procariontes, que son organismos bacterianos y arqueas (bacterias antiguas) la mayoría unicelulares cultivables y no cultivables.
Contacto: maricela.carrera@ibt.unam.mx; veronica.jimenez@ibt.unam.mx; rosa.gutierrez@ibt.unam.mx