

Ecos del algoritmo: la evolución de la bioinformática en México.
Verónica Jiménez Jacinto, Shirley Ainsworth, Maricela Carrera Reyna y Rosa María Gutiérrez Ríos
En el artículo “Descifrando la información genética”, publicado en este número, te contamos cuáles fueron los descubrimientos más importantes que nos llevaron a poder desarrollar las ciencias-ómicas y la bioinformática. Ahora, en este artículo, te contaremos quiénes han sido las mujeres que han contribuido al desarrollo de la bioinformática.
Aunque el trabajo de muchos científicos y los avances en la tecnología han contribuido a dar forma a la bioinformática como la conocemos ahora, su historia se remonta a la época en que el poder de cómputo era limitado y los lenguajes de programación estaban poco desarrollados. La primera mujer programadora fue Ada Lovelace (Figura 1), que en 1833 trabajó con Charles Babbage (quien ha sido considerado como “el padre de las computadoras”), aún antes de la construcción de la primera computadora electrónica. Ambos predijeron en su momento la existencia de lo que hoy conocemos como Inteligencia Artificial, de la que dependen muchos procesos realizados por nuestros teléfonos inteligentes, y hasta la infraestructura de muchas ciudades en el mundo.

Figura 1. Ada Lovelace, matemática y escritora inglesa considerada la primera programadora informática de la historia (Ilustración: Mariana Caballero Jiménez).
A mediados del siglo pasado, aparece Grace Murray Hopper (Figura 2); una matemática nacida en los Estados Unidos pionera de la programación informática. Es la creadora de los lenguajes de programación FLOW-MATIC y COBOL denominados de “alto nivel”. Estos lenguajes realizan una abstracción que permite hacer más comprensible el código haciendo uso de elementos como el lenguaje natural, variables y estructuras de control, entre otros, que pueden generar un código muy eficiente y fácil de entender. Ejemplos de lenguajes de alto nivel incluyen C++, Fortran, Java, Perl, PHP y Python, que se emplean en el desarrollo de muchas aplicaciones informáticas y bioinformáticas.

Figura 2. Grace Murray Hopper, matemática y pionera en la creación de lenguajes de programación (Ilustración: Mariana Caballero Jiménez).
Los avances en la forma de programar, así como aquellos generados por la bioquímica y biología molecular (leer “Descifrando la información genética” en este número), permitieron que apareciera nuestra primera mujer en la bioinformática; la química Margaret Oakley Dayhoff, considerada como la “madre y padre” de esta ciencia (Figura 3), nombramiento que le otorgó el científico David J. Lipman, quien fue director del Centro Nacional de Biotecnología e Información de los Estados Unidos (NCBI por sus siglas en inglés).

Figura 3. Margaret Oakley Dayhoff, considerada la madre de la bioinformática, creó los primeros programas para el análisis de las secuencias biológicas (Ilustración: Mariana Caballero Jiménez).
Dayhoff hizo su doctorado en química cuántica, en donde se combinaron sus conocimientos en cómputo y química teórica para calcular las energías de resonancia de varias moléculas orgánicas policíclicas. Pero te preguntarás, ¿qué son las energías de resonancia y las moléculas orgánicas policíclicas? Imagina que tienes varias piezas de Lego conectadas entre sí. Al unirlas de una manera en la que los bloques pueden distribuir el peso de manera uniforme, la estructura será más estable. Pero si las piezas no encajan bien o si hay tensión en algunas partes, la estabilidad disminuye.
Las energías de resonancia en moléculas policíclicas funcionan de una forma parecida, ya que están formadas por varios anillos conectados, y su estabilidad depende de cómo se distribuyen los electrones en su estructura.
Un buen ejemplo de esto es el naftaleno, un compuesto con dos anillos fusionados. En éste, los electrones no están fijos en enlaces individuales, sino que se mueven libremente por toda la estructura, en un fenómeno llamado “deslocalización electrónica” (Figura 4). Esto significa que, en lugar de tener enlaces simples y dobles bien definidos, los electrones están distribuidos de manera uniforme, formando una especie de "nube" sobre los anillos. Esta deslocalización hace que el naftaleno sea más estable, de manera similar a los bloques de Lego bien distribuidos. Dayhoff, tomó al naftaleno y a móleculas de otros compuestos aromáticos y escribió un código para calcular sus energías de resonancia, que puso en tarjetas perforadas. Estas tarjetas, eran láminas hechas de cartulina con perforaciones organizadas en un patrón específico que representan información codificada, y que fueron utilizadas para almacenamiento de información computacional. Desde entonces Dayhoff vio el potencial de las computadoras para realizar análisis de la información química y biológica.
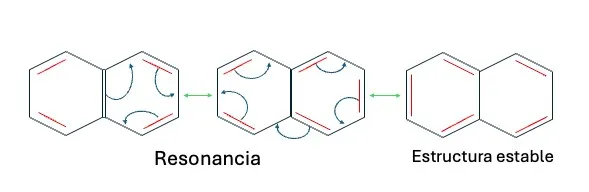
Figura 4. Energías de resonancia del naftaleno. La figura ilustra cómo la resonancia, representada con flechas azules, contribuye a lograr una estructura estable en la molécula de naftaleno. Las flechas verdes aluden a los pasos necesarios para que el naftaleno alcance su estabilidad.
Las contribuciones de Dayhoff a la bioinformática dieron lugar al primer programa para el análisis de secuencias de proteínas llamado COMPROTEIN [1], que desarrolló en colaboración con Robert S. Ledley, pionero, al igual que Dayhoff, en el uso de computadoras digitales electrónicas en biología y medicina.
COMPROTEIN fue el primer programa diseñado para determinar la estructura primaria de las proteínas utilizando datos de secuenciación de péptidos de Edman (leer el artículo “Descifrando la información genética” en este número). Este programa sentó las bases de los programas que hoy conocemos como ensambladores de secuencias de novo, que se refiere a la observación de secuencias de ADN no descritas previamente. Adicionalmente, una de las novedades de este programa fue la introducción de un código de tres letras que describe a cada aminoácido que forma a las proteínas en donde por ejemplo lisina (codificada en el genoma como AAA o AAG), se expresó como Lys (L) y así para cada aminoácido, lo que permitía manejar más fácilmente las secuencias de aminoácidos (Figura 5).
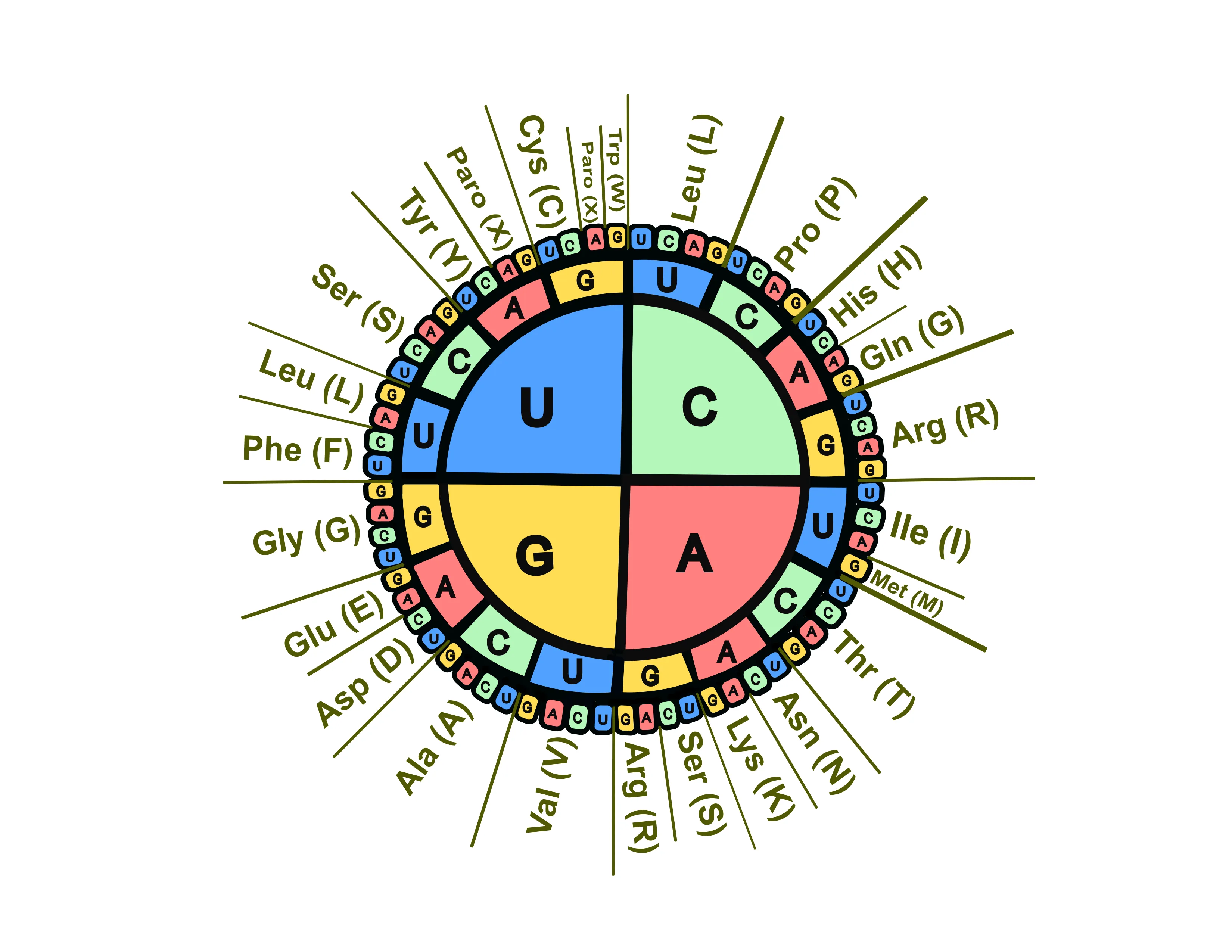
Figura 5. El código genético define cada aminoácido de una proteína o polipéptido en términos de una secuencia específica de tres nucleótidos llamados codones. Se presenta también el código de una letra usada para el análisis de secuencias de aminoácidos y publicado en el Atlas de secuencia y estructura de proteínas.
Posteriormente, Dayhoff desarrollaría el código de una sola letra para describir a los aminoácidos de las proteínas que sirvió para que, en conjunto con Marie A. Chang y Minnie R. Sochard, publicaran el Atlas de secuencia y estructura de proteínas [2], que fue la primera base de datos de proteínas disponible en 1965, y que derivó en lo que en la actualidad conocemos como la Colaboración Internacional de Bases de datos de secuencias de nucleótidos (International Nucleotide Sequence Database Collaboration o [INSD, por sus siglas en inglés)](https://www.insdc.org/) en donde se comparte de manera pública cualquier secuencia que haya sido descrita en alguna publicación científica a través de repositorios, como el Laboratorio Europeo de Biología Molecular - Archivo Europeo de Nucleótidos (EMBL-ENA siglas en inglés), el Banco de datos de ADN de Japón (DDBJ por su siglas en inglés) y el Centro Nacional de Información Biotecnológica de los Estados Unidos de América (NCBI por sus siglas en inglés). Estos repositorios se comparten, coordinan y ponen disponible públicamente toda la información genómica que poseen, así como herramientas para analizar, comparar e inspeccionar este gran acervo informativo.
Bioinformática en México
Aunque es difícil dar una fecha exacta en la que inicia el uso y desarrollo de las herramientas bioinformáticas en México, se conocen algunos datos de cómo pudo haberse introducido a México esta área del conocimiento. Una forma de evaluar esto, es observando el número de publicaciones científicas de corriente principal (aquellas indizadas en bases de datos internacionales de prestigio), en las que participa la comunidad científica mexicana con adscripción a instituciones nacionales, lo cual puede apreciarse en la Figura 6, que muestra el incremento del uso de herramientas informáticas en distintas áreas de la biología.
Como puedes observar en la Figura 6, en el año 1988, en la base de datos Scopus solo existe una publicación. El corte hecho hasta el año 2024 muestra como se ha incrementado el número de publicaciones en bioinformática hasta alcanzar más de 300 por año. Una inspección visual de los datos, que no se muestra en la figura, Nos dice que la contribución de las mujeres en los primeros años era escasa; sin embargo, a lo largo del tiempo, lentamente se ha ido incrementando el número de mujeres que participan en investigaciones de distintos temas en los que la bioinformática ha jugado un papel importante.
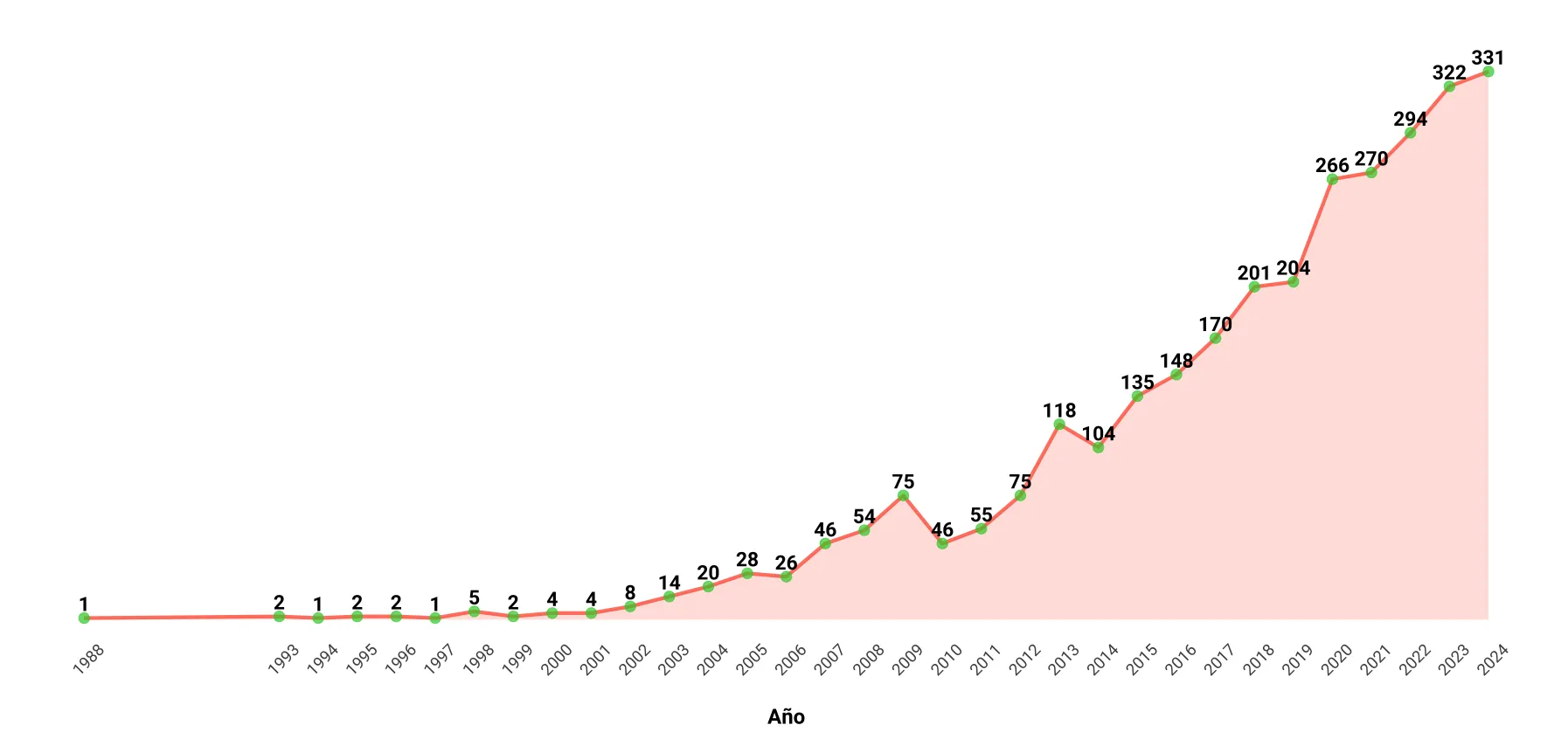
Figura 6. Evolución de la bioinformática en México. Distribución del número de publicaciones por año de la comunidad científica mexicana trabajando en instituciones nacionales reportadas en la base de datos Scopus.
Un análisis bibliométrico publicado en el año 2022 [3], hace una revisión exhaustiva tomando una ventana de 25 años, con el objetivo de identificar a los autores e instituciones mexicanas que tienen mayor impacto internacional en el área de bioinformática. De acuerdo con sus resultados, la UNAM aporta un total de 1,326 publicaciones, destacando las contribuciones del Centro de Ciencias Genómicas y del Instituto de Biotecnología, ambos de la UNAM. En tanto que fuera de la UNAM, el Instituto Politécnico Nacional aporta un total de 553, teniendo el segundo lugar en cuanto a producción de artículos internacionales relacionados con genómica, bioinformática y temas afines
En este análisis, Julio Collado, investigador del Centro de Ciencias Genómicas, es el científico que ha aportado el mayor número de publicaciones. Las autoras con el mayor número de publicaciones son Heladia Salgado (leer “El sitio Regulon DB: Construyendo el Mapa de la Regulación Genética en Escherichia coli”, en este número) y Socorro Gama-Castro, ambas del Centro de Ciencias Genómicas, contribuyendo con 24 y 20 publicaciones respectivamente, en el periodo comprendido entre 1994 y 2018.
En cuanto a la creación de laboratorios de investigación en el área de genómica y bioinformática, está documentado que, en 1992, Julio Collado se incorpora a la UNAM creando el primer laboratorio de Biología Computacional. Este laboratorio está ubicado en Cuernavaca, en el Centro de Ciencias Genómicas y ha tenido la visión de formar un equipo interdisciplinario de investigadores con formación en computación, matemáticas, física, biología y química. Este laboratorio, sin duda, ha sido semillero de grandes bioinformáticas mexicanas.
En el año 2003, entusiastas académicos del Centro de Ciencias Genómicas y del Instituto de Biotecnología, ambos pertenecientes a la UNAM, comprometidos con la formación de profesionales en el área de genómica y bioinformática, crearon la primera licenciatura en Ciencias Genómicas (https://www.lcg.unam.mx/) del país y de muchos países latinoamericanos, que hasta la fecha cubre las necesidades de profesionistas con amplias capacidades bioinformáticas. En la Figura 7, te presentamos una línea de tiempo que resume los avances y contribuciones que han dado forma a la bioinformática como la conocemos ahora en el mundo y en nuestro país.
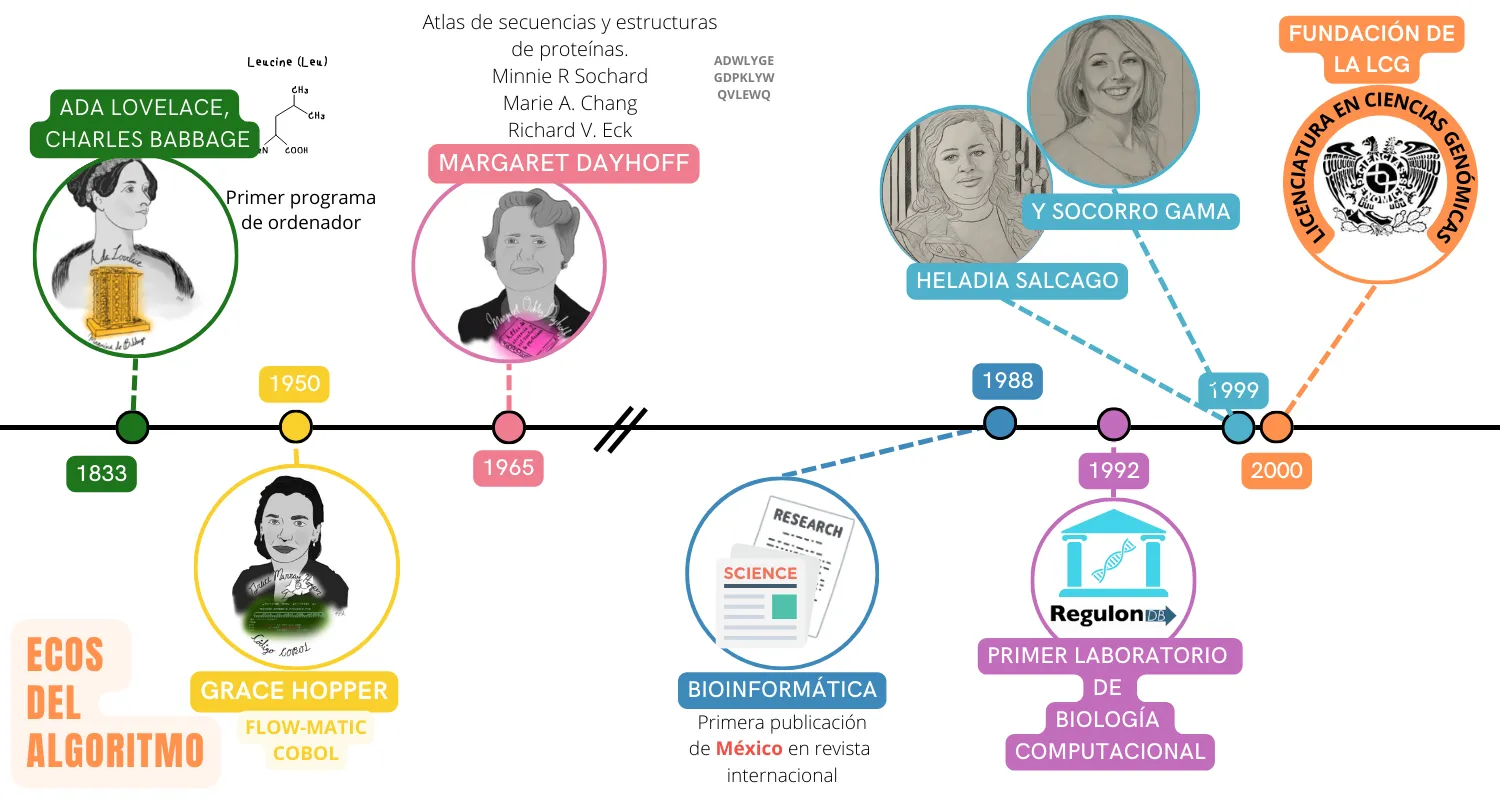
Figura 7. Línea de tiempo. Principales contribuciones que dieron forma a la bioinformática y algunas de las mujeres que lo han hecho posible.
Adicionalmente, como podrás leer en los artículos “Python: más allá del código” y “R-Ladies: Promoviendo la inclusión en el lenguaje R”, que forman parte de esta edición, existen ahora diferentes iniciativas lideradas por científicas mexicanas como PyLadies y RLadies, que son pilares en la formación y el desarrollo de la bioinformática en México.
Referencias
- Franco M., Cediel J., y Payan C., Breve historia de la bioinformática. Colombia Médica. Vol. 39 Nº 1, 2008 (Enero-Marzo)
- Dayhoff, M. O. (Ed.). (1965). Atlas of Protein Sequence and Structure. National Biomedical Research Foundation.
- Armenta-Medina D, Díaz de León Castañeda C, Armenta-Medina A, Perez-Rueda E. A Bibliometric Analysis of Mexican Bioinformatics: A Portrait of Actors, Structure, and Dynamics. Biology (Basel). 2022 Jan 13;11(1):131. DOI: [10.3390/biology11010131 ](https://doi.org/10.3390/biology11010131)
Lecturas recomendadas
- Angélica Jara Servín (2021) El poder de la bioinformática ¿Como ves? 272 https://www.comoves.unam.mx/numeros/articulo/272/el-poder-de-la-bioinformatica
- Serrano, José A Bioinformática y genética Ciencia UANL, México, 2014 Vol. 17 Núm. 65 Ene-Feb, Pág. 7-8 https://cienciauanl.uanl.mx/?p=723
Comparte este artículo en redes sociales

Acerca de las autoras
Verónica Jiménez estudió la licenciatura en Matemáticas aplicadas y computación. Ha trabajado en proyectos bioinformáticos durante los últimos 23 años. Participó en la secuenciación de uno de los primeros organismos secuenciados en Latinoamérica: Rhizobium etli, en 2006. Es co-fundadora de RLadies Cuernavaca y tiene la certificación de Software Carpentries para la formación de instructores de en distintos lenguajes de programación. También es la responsable del sistema de Gestión de Calidad de ISO 9001 del Laboratorio Nacional de Apoyo Tecnológico a las Ciencias Genómicas. Shirley Ainsworth es jefa de la Unidad de Biblioteca del Instituto de Biotecnología. Sus intereses incluyen recursos electrónicos de información, bibliometría e integridad científica. Maricela Carrera Reyna es estudiante de doctorado en el posgrado de Ciencias Bioquímicas de la UNAM, con interés en la aplicación de métodos computacionales para la exploración de genomas microbianos. Es especialista en lenguajes de programación y socia fundadora de PyLadies Cuernavaca. Rosa María Gutiérrez Ríos es investigadora del IBt en el área de genómica y biología computacional. Sus investigaciones están enfocadas en entender a nivel de sistema, las interacciones genético-metabólicas que modulan la expresión de los genes en procariontes cultivables y no cultivables en condiciones de laboratorio.
Contacto: veronica.jimenez@ibt.unam.mx; rosa.gutierrez@ibt.unam.mx.