

Python: más allá del código
Edna Cruz-Flores y Maricela Carrera-Reyna
Un lenguaje de programación es como un idioma que usamos para hablar con las computadoras. Con él, podemos darles instrucciones para realizar tareas específicas, como resolver problemas, crear aplicaciones, analizar datos o controlar dispositivos. Así como usamos palabras y reglas gramaticales para comunicarnos entre personas, los lenguajes de programación tienen sus propias palabras (código) y reglas (sintaxis) que las computadoras entienden. Algunos, como Python, son más simples y fáciles de aprender, mientras que otros son más técnicos y complejos.
Python, en particular, es un lenguaje de programación que, más que una herramienta técnica, se ha convertido en un aliado para simplificar tareas complejas. Es como el idioma universal de la tecnología: fácil de entender, flexible y poderoso. Creado en 1991 por Guido van Rossum, Python se diseñó con un objetivo muy claro: que cualquier persona, desde un principiante hasta un experto, pueda escribir código de manera intuitiva y eficiente.
A diferencia de otros lenguajes que pueden parecer un rompecabezas, Python usa una sintaxis que casi se lee como se lee el inglés. Esto lo hace ideal para aprender a programar, pero también es tan robusto que empresas gigantes como Google, Netflix, Spotify y NASA lo usan para proyectos que van desde inteligencia artificial hasta el control de robots y desarrollo de aplicaciones.
Además de su versatilidad, Python cuenta con una comunidad global que colabora constantemente para mejorar el lenguaje, compartir recursos y crear herramientas que amplían sus capacidades. Esto lo convierte en una opción accesible para todos, ya que es de código abierto y se puede usar de forma gratuita.
El nombre Python no tiene nada que ver con serpientes, aunque podría parecerlo. En realidad, Guido van Rossum, el creador del lenguaje se inspiró en un programa de televisión británico llamado "Monty Python’s Flying Circus". Este programa de comedia, famoso por su humor absurdo y creativo, era uno de los favoritos de Guido mientras desarrollaba el lenguaje en los años 90.
Quería un nombre que fuera corto, único y un poco misterioso, algo que capturara la esencia divertida y accesible de lo que estaba creando. Así, eligió "Python", un nombre que hoy representa no solo un lenguaje de programación, sino también una filosofía de diseño simple y poderosa.
Según el índice TIOBE, una clasificación que mide la popularidad de los lenguajes de programación a nivel mundial, Python es actualmente el lenguaje de programación más popular, ocupando la primera posición por encima de C++ y Java, que se encuentran en segundo y tercer lugar respectivamente. Su popularidad radica en que es ampliamente preferido tanto para aprender a programar como para desarrollar proyectos de software.
Python no solo es popular por su diseño simple, sino también por su extenso ecosistema de librerías (módulos o bibliotecas), que son colecciones de código reutilizable diseñadas para resolver problemas específicos sin necesidad de reescribir código desde cero. Estas pueden estar escritas en Python o en otros lenguajes de programación, pero están diseñadas para integrarse y funcionar dentro del entorno de Python. Estas librerías abarcan diversas áreas del conocimiento.
En la Figura 1 se presentan ejemplos de estas librerías organizados por áreas de aplicación.
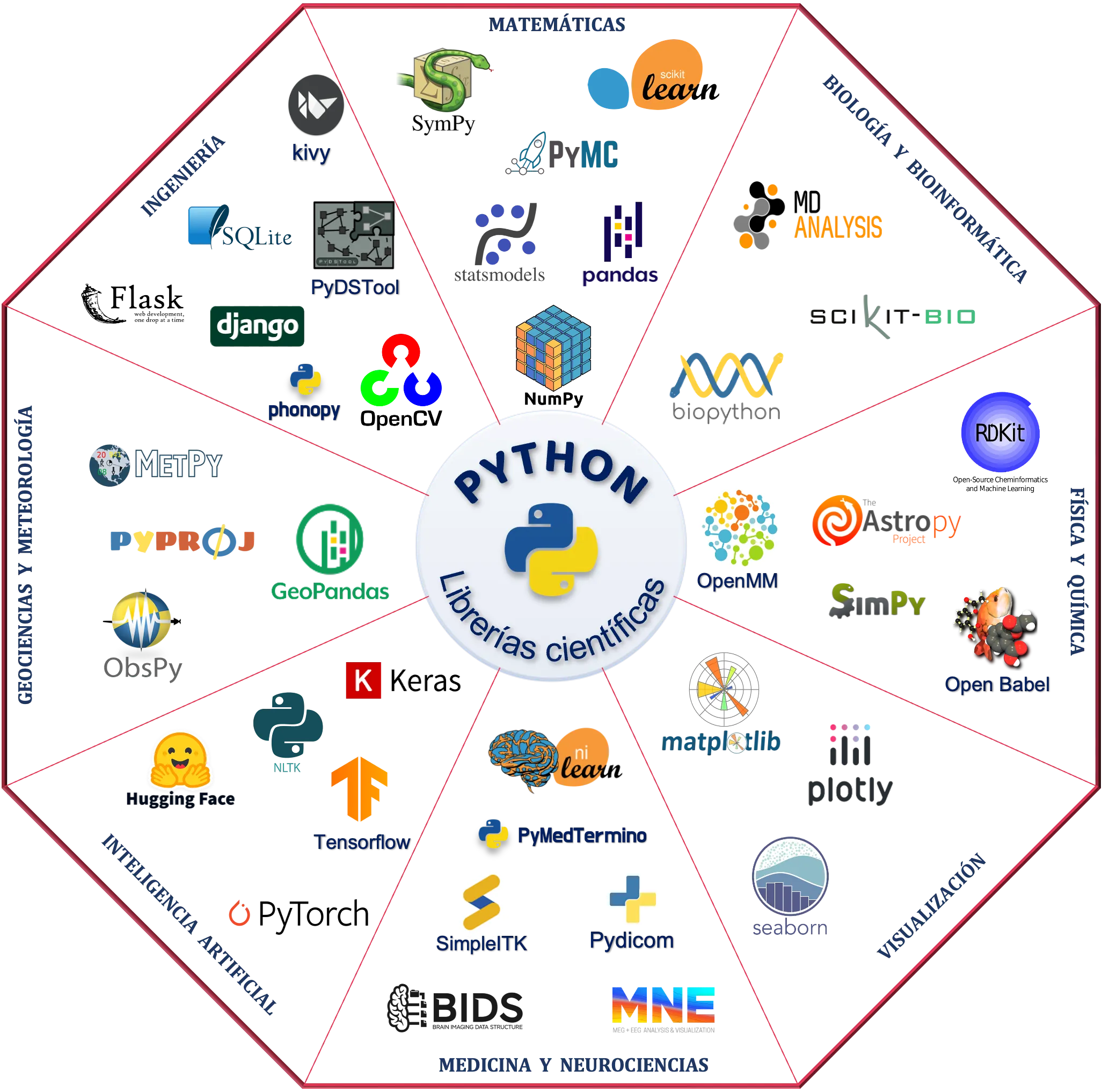
Figura 1. Algunas de las librerías especializadas de python divididas por áreas de estudio.
Su capacidad para conectar diferentes áreas del conocimiento ha fomentado la colaboración interdisciplinaria, acelerando avances en campos como la física, la química, la biología y la inteligencia artificial, entre otras tantas. Pero su impacto no se limita a la ciencia: también impulsa las tecnologías que usamos todos los días, como asistentes virtuales, plataformas de streaming y aplicaciones móviles, algunas listadas en la Figura 2.

Figura 2. Usos destacados del lenguaje de programación Python en la vida cotidiana. La figura muestra ejemplos de aplicaciones prácticas como predicción de movimientos en deportes, exploración espacial y análisis climático, creación de películas y efectos especiales, asistentes personales basados en inteligencia artificial, desarrollo de videojuegos y aplicaciones, y generación de música y arte.
Python en ciencias biológicas y biotecnología: un lenguaje para la Innovación
Python ha transformado la investigación en ciencias de la vida gracias a su facilidad de uso y a una gran variedad de librerías especializadas (Figura 1). Su aplicación en el análisis de datos biológicos permite estudiar, por ejemplo: el ADN y proteínas, entender enfermedades, modelar procesos celulares y realizar simulaciones complejas de manera eficiente.
Este campo, conocido como bioinformática, combina biología, computación y estadística para interpretar la enorme cantidad de información generada al estudiar los seres vivos. Gracias a estas herramientas, es posible responder preguntas clave sobre salud, evolución y el desarrollo de nuevos tratamientos
Flujos de trabajo en bioinformática y Python
Los flujos de trabajo en bioinformática son procesos estructurados y de múltiples etapas que permiten transformar datos biológicos en conocimiento. Algunas de las fases clave incluyen:
• Extracción de datos y metadatos: Obtención de datos biológicos desde repositorios públicos o experimentos propios.
• Procesamiento y limpieza de los datos: Aplicación de controles de calidad, filtrado y normalización de los datos y sus metadatos.
• Análisis y visualización de los datos: Exploración mediante métodos estadísticos, herramientas computacionales y gráficos para identificar patrones o tendencias relevantes.
• Integración de datos: Combinación de información biológica para obtener una visión más completa del sistema estudiado.
• Modelado y extracción de conocimiento: Uso de estadística, inteligencia artificial y otras técnicas computacionales para interpretar datos y resolver problemas específicos en biología y biotecnología.
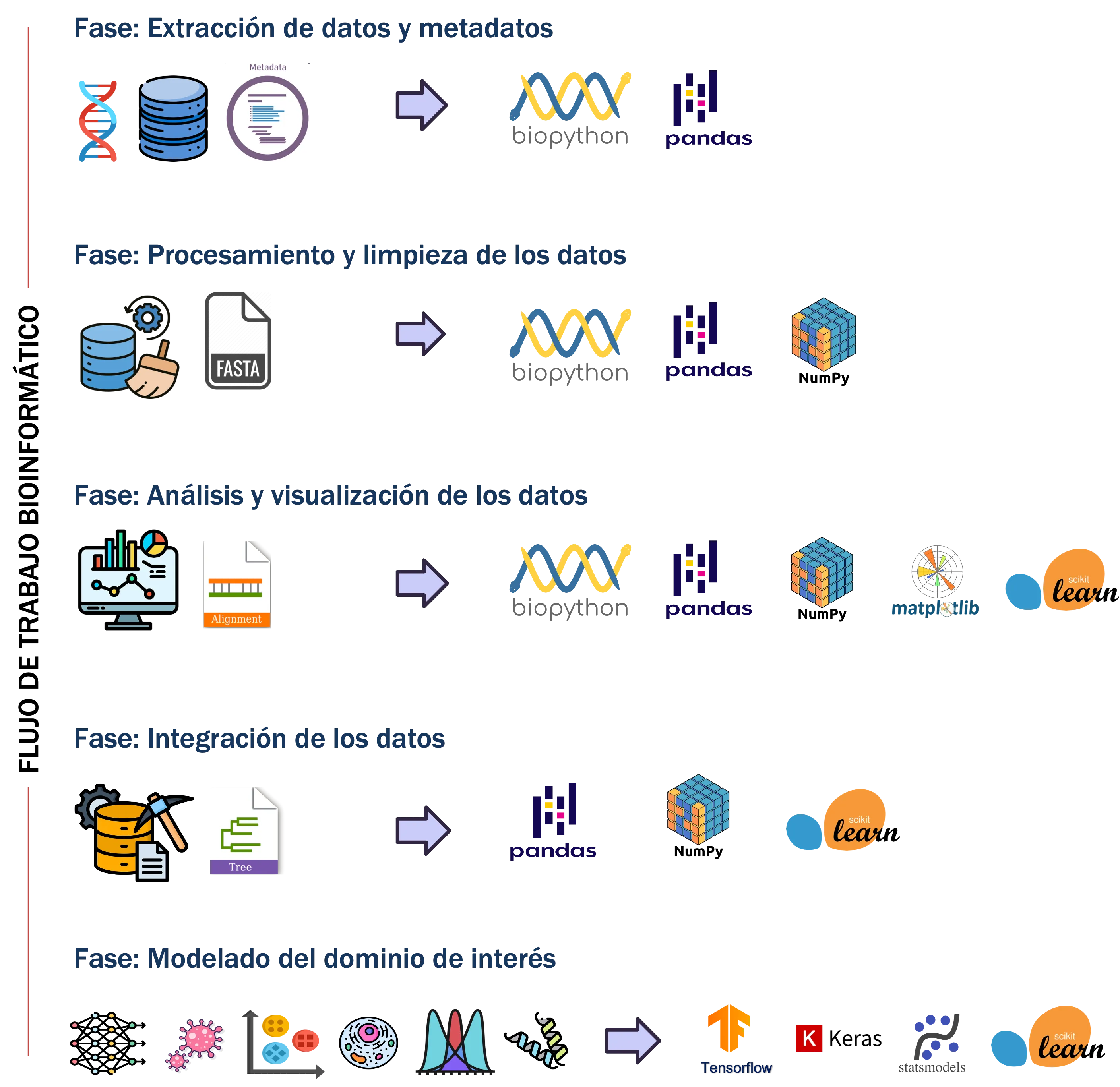
Figura 3. Representación de las principales fases de los flujos de trabajo en bioinformática y las librerías de Python comúnmente utilizadas en cada una de ellas.
Aplicaciones de Python en la bioinformática y la inteligencia artificial
Python ha sido una herramienta clave en la vigilancia genómica del SARS-CoV-2, especialmente durante la pandemia. Gracias a sus capacidades, fue posible analizar la evolución del virus, rastrear nuevas variantes, evaluar su impacto en la transmisión y la efectividad de las vacunas, así como diseñar estrategias para mitigar su propagación.
Sin embargo, cuando los datos son demasiado complejos para ser analizados manualmente, la inteligencia artificial entra en juego. En particular, el aprendizaje profundo, una rama de la inteligencia artificial, permite desarrollar modelos computacionales capaces de identificar patrones en grandes volúmenes de datos sin necesidad de una revisión humana caso por caso. Estos modelos no solo encuentran relaciones ocultas en la información, sino que también pueden realizar predicciones basadas en lo aprendido.
Aplicado a la biotecnología, el aprendizaje profundo facilita el análisis de secuencias biológicas y la identificación de patrones complejos en el ADN y las proteínas. Con librerías como Scikit-learn, TensorFlow, Keras y PyTorch, es posible entrenar modelos de predicción que aprenden de datos previos y realizan estimaciones en nuevos casos.
Por ejemplo, se pueden desarrollar modelos para la clasificación de virus analizando secuencias de ADN [1] o secuencias de proteínas [2]. Además, el aprendizaje profundo permite predecir regiones conservadas en los genomas, como las secuencias que conforman el sistema CRISPR-Cas en bacterias. Este sistema actúa como un mecanismo de defensa adaptativo, permitiendo a las bacterias reconocer y protegerse de infecciones causadas por bacteriófagos (virus que infectan bacterias). Mediante el análisis de los arreglos CRISPR, es posible estudiar las interacciones entre bacterias y virus a lo largo del tiempo, proporcionando información clave sobre su evolución [3].
AlphaFold: revolucionando la predicción de estructuras de proteínas
Uno de los avances más impresionantes en el uso de la inteligencia artificial en biología es AlphaFold, un sistema desarrollado por la empresa de inteligencia artificial, DeepMind, que ha revolucionado la predicción de estructuras de proteínas. Las estructuras de proteínas son la forma tridimensional en la que se pliegan las cadenas de aminoácidos que las componen. Esta estructura es clave para entender su función, ya que una proteína necesita adoptar una forma específica para realizar su tarea dentro de una célula (ver el número el artículo de este número "Descifrando la información genética").
Antes de AlphaFold, determinar la forma tridimensional de una proteína era un proceso largo y costoso, que dependía de técnicas experimentales como la cristalografía de rayos X o la resonancia magnética nuclear. Es interesante mencionar que AlphaFold está desarrollado principalmente en Python y utiliza TensorFlow y JAX, dos marcos de trabajo para el aprendizaje profundo. Además, emplea bibliotecas como NumPy y Biopython para manejar datos biológicos y cálculos matemáticos. JAX, en particular, optimiza el rendimiento de los cálculos en hardware, lo que permite entrenar modelos de predicción de estructuras de proteínas de manera eficiente.
AlphaFold utiliza redes neuronales profundas para predecir con alta precisión cómo se pliega una proteína a partir de su secuencia de aminoácidos. Esto ha abierto nuevas puertas en la investigación biomédica, permitiendo comprender de mejor manera enfermedades, diseñar nuevos fármacos y explorar funciones biológicas con una rapidez sin precedentes. Gracias a su impacto, AlphaFold ha sido considerado uno de los mayores avances científicos de los últimos tiempos y su código abierto ha permitido a investigadores de todo el mundo aplicarlo a diversos problemas en biotecnología y medicina.
➣ Python no solo es un lenguaje de programación; es una puerta de entrada al mundo de la tecnología, accesible para cualquiera con curiosidad y ganas de aprender.
Las comunidades para aprender Python
Python ha inspirado la creación de movimientos que democratizan el acceso a la programación y la tecnología. En todo el mundo existen iniciativas adaptadas a distintos niveles y objetivos, como Django Girls, la Python Software Foundation (PSF), PyData, Google’s Python Class, Women Who Code, PyLadies, PyconLatam, entre otras. Estas organizaciones y eventos ofrecen oportunidades para aprender, compartir conocimientos y colaborar en proyectos innovadores.
Entre estas iniciativas destaca PyLadies Global (https://pyladies.com), una organización internacional cuyo nombre proviene de “Py” por Python y “Ladies” por mujeres. Su objetivo es empoderar a mujeres, minorías de género (como personas no binarias y transgénero) y aliados, fomentando un entorno seguro, inclusivo y colaborativo donde se pueden intercambiar ideas y desarrollar proyectos de impacto.
Si bien muchas de estas iniciativas están enfocadas en Python, también han surgido comunidades dedicadas a otros lenguajes. Un ejemplo es R-Ladies, un espacio pionero que impulsa la inclusión en el aprendizaje del lenguaje R, con especial énfasis en análisis de datos y estadística. Como se verá en el artículo “R-Ladies: promoviendo la inclusión en el lenguaje de programación R”, ambas comunidades comparten la visión de fomentar la diversidad y el empoderamiento femenino en el ámbito tecnológico.
PyLadies, al igual que R-Ladies, opera a través de capítulos locales en diversas ciudades del mundo. En México, la comunidad ha ido creciendo y actualmente cuenta con presencia en Ciudad de México, Monterrey, Guadalajara, Puebla y, más recientemente, Cuernavaca. Este último capítulo surgió en febrero de 2024 para responder a la necesidad de un espacio accesible donde cualquier persona pudiera aprender programación desde cero, sin importar su formación académica o experiencia previa.
La primera reunión se llevó a cabo en el Instituto de Biotecnología de la UNAM, campus Morelos, y desde entonces se han organizado nueve sesiones exitosas (Figura 4). Además, se han fortalecido lazos con otros capítulos, como PyLadies Monterrey (con la ponencia de Ludim Sanchez-Chica Dev) y PyLadies CDMX (con la ponencia de Yalbi Balderas), promoviendo el aprendizaje colaborativo y el intercambio de experiencias (Figura 5).
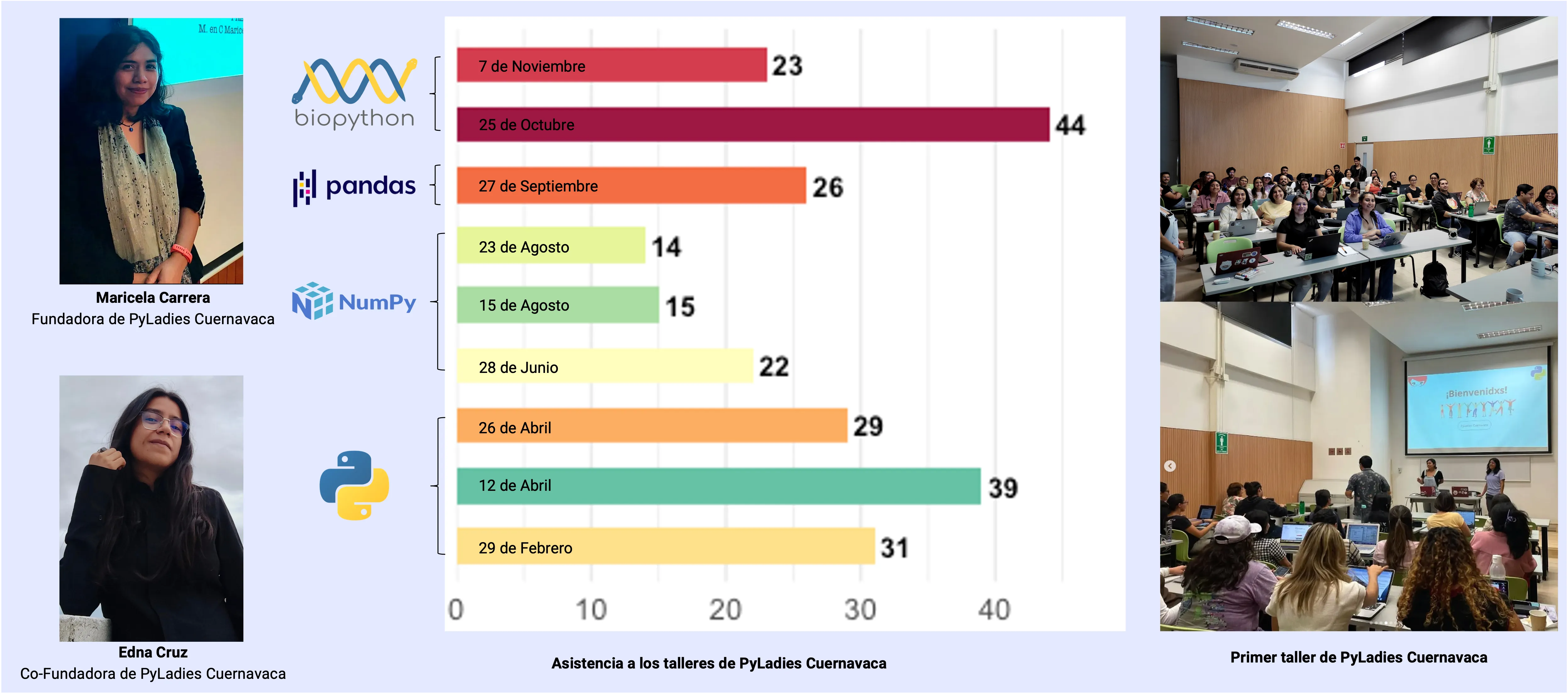
Figura 4. Asistencia presencial y virtual a los talleres organizados por PyLadies Cuernavaca.
Más allá de ofrecer conocimientos técnicos sobre Python, estas iniciativas construyen redes de apoyo y colaboración, haciendo del aprendizaje una experiencia enriquecedora y accesible para todas las personas.
Si estás en Cuernavaca, te invitamos a ser parte de esta comunidad. Síguenos en nuestras redes sociales para mantenerte informado sobre los próximos eventos y únete a esta emocionante iniciativa que está transformando la manera en que aprendemos y aplicamos Python. ¡Visita nuestra página web (https://pyladies-cuernavaca.quarto.pub/web/) y comencemos a aprender juntxs!

Figura 5. Colaboraciones a impartir talleres de PyLadies Cuernavaca en el periodo Febrero – Diciembre del año 2024.
Referencias
- Cadenas-Castrejon, E., Verleyen, J., Boukadida, C., Diaz-Gonzalez, L., Taboada, B. (2023). Evaluation of tools for taxonomic classification of viruses. Briefings in Functional Genomics, 22 (1), 31-41. DOI: 10.1093/bfgp/elac036.
- Zarate, A., Diaz-Gonzalez, L., Taboada, B. (2025). VirDetect-AI: a residual and convolutional neural network-based metagenomic tool for eukaryotic viral protein identification. Briefings in Bioinformatics, 26 (1), bbaf001. DOI: 10.1093/bib/bbaf001.
- Cruz Flores, Edna (2022). Herramienta computacional para la caracterización de matrices CRISPR. Facultad de Contaduria, Adminstracion e Informatica, Maestra en Optimización y Cómputo Aplicado, UAEM. Asesor: Díaz González, Lorena, Taboada-Ramirez, Blanca Itzelt.
Lecturas recomendadas
- Lutz, Mark. Learning Python: Powerful Object-Oriented Programming. Estados Unidos: O'Reilly Media, Incorporated, 2025. Este artículo de DataCamp discute las razones por las cuales Python es beneficioso para la computación científica y cómo la comunidad de Python puede apoyar efectivamente la investigación científica. https://www.datacamp.com/blog/the-case-for-python-in-scientific-computing.
- Harris, C.R., Millman, K.J., van der Walt, S.J. et al. Array programming with NumPy.Nature 585, 357–362 (2020). Explora cómo NumPy, una biblioteca fundamental en el ecosistema científico de Python, facilita la programación con arreglos y su aplicación en campos como física, química y astronomía. Además, da un panorama general del uso del ecosistema de python en múltiples disciplinas. DOI: 10.1038/s41586-020-2649-2.
- De Régules, S. (2024). Premios Nobel 2024. Revista ¿Cómo ves? Núm. 313. El artículo explica cómo el Premio Nobel de Química 2024 reconoce avances impulsados por la inteligencia artificial en la predicción de la estructura de proteínas a partir de sus secuencias de aminoácidos, destacando el impacto de AlphaFold de Google DeepMind y el trabajo pionero de David Baker en el diseño de proteínas. https://www.comoves.unam.mx/numeros/rafagas/313.
- Manjarrez, A. (2023). Plegando proteínas. Revista ¿Cómo ves? Núm. 294. El artículo narra la evolución en la determinación de la estructura de proteínas, desde los primeros experimentos con cristalografía de rayos X usando muestras inusuales (como la carne de cachalote) hasta el uso de inteligencia artificial, en particular con AlphaFold 2, que ha revolucionado la predicción de estructuras proteicas en minutos. Además, se destacan los logros y limitaciones actuales de la IA en este campo, evidenciando que aún quedan retos por superar en la comprensión completa del plegamiento de proteínas. https://www.comoves.unam.mx/numeros/articulo/294/plegando-proteinas.
Comparte este artículo en redes sociales

Acerca de las autoras
M.O.C.A Edna Cruz-Flores es estudiante de Doctorado en Ciencias, Instituto de Ciencias Básicas y Aplicadas, UAEM. Su interés se centra en la Ciencia de Datos, la Bioinformática y el desarrollo de modelos de Aprendizaje Profundo, aplicando algoritmos avanzados como redes neuronales profundas para el análisis de datos biológicos. Su trabajo busca integrar herramientas bioinformáticas y de inteligencia artificial en la exploración y comprensión de información en las ciencias de la vida. Maricela Carrera Reyna es estudiante de doctorado del posgrado en Ciencias Bioquímicas, de la UNAM. Es con interés en la aplicación de métodos computacionales para la exploración de genomas microbianos. Además, es socia fundadora de PyLadies Cuernavaca, un capítulo local de la comunidad global PyLadies, dedicado a enseñar Python y reducir la brecha de género en tecnología. A través de esta iniciativa, trabaja en la creación de espacios de aprendizaje inclusivos para mujeres, minorías de género (incluyendo personas no binarias y transgénero) y aliados interesados en la programación. Su labor en comunidad busca empoderar a más personas en el uso de herramientas computacionales y fomentar la participación de grupos subrepresentados en la ciencia y la tecnología.
Contacto: edna.cruz@ibt.unam.mx; maricela.carrera@ibt.unam.mx